DSANet
This "Dual Self-Attention Network for Multivariate Time Series Forecasting" is based on the paper by Siteng Huang et. al..
The code is based on a PyTorch implementation of the same model with slight adjustments.
Network Structure
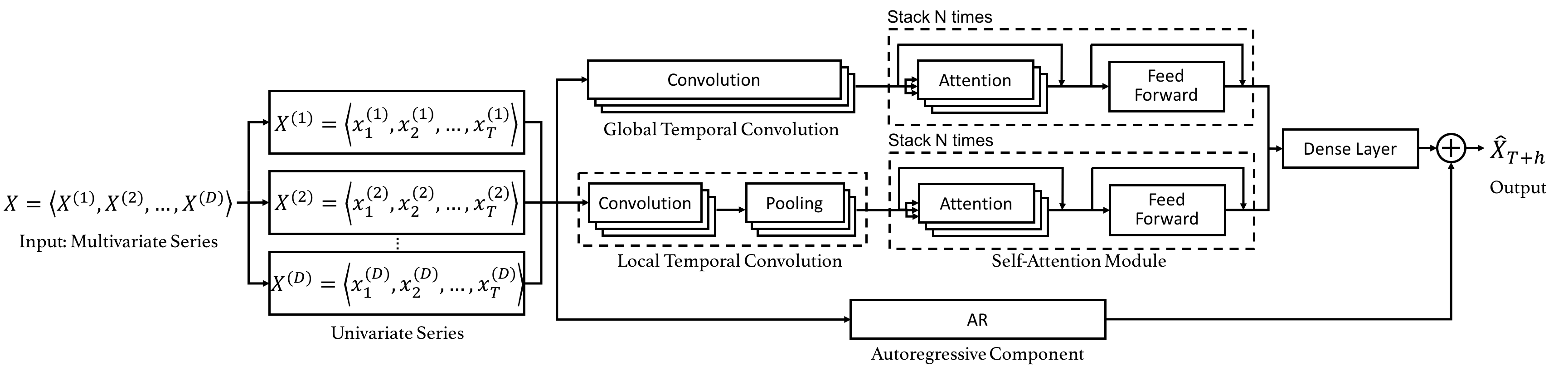
The neural net consists of the following elements:
- An autoregressive part
- A local temporal convolution mechanism, fed to a self-attention structure.
- A global temporal convolution mechanism, fed to a self-attention structure.
Known Issues
The
MaxPoolpooling layers in the temporal convolution mechanisms can cause the model output to becomeNaNduring training. This is not captured yet. Changing the model parameters or the random seed before training can help.The original model transposes some internal matrices, using
Flux.batched_transpose. As there is no adjoint defined yet for this operation inZygote.jl, we usepermutedimsinstead.