TPA-LSTM
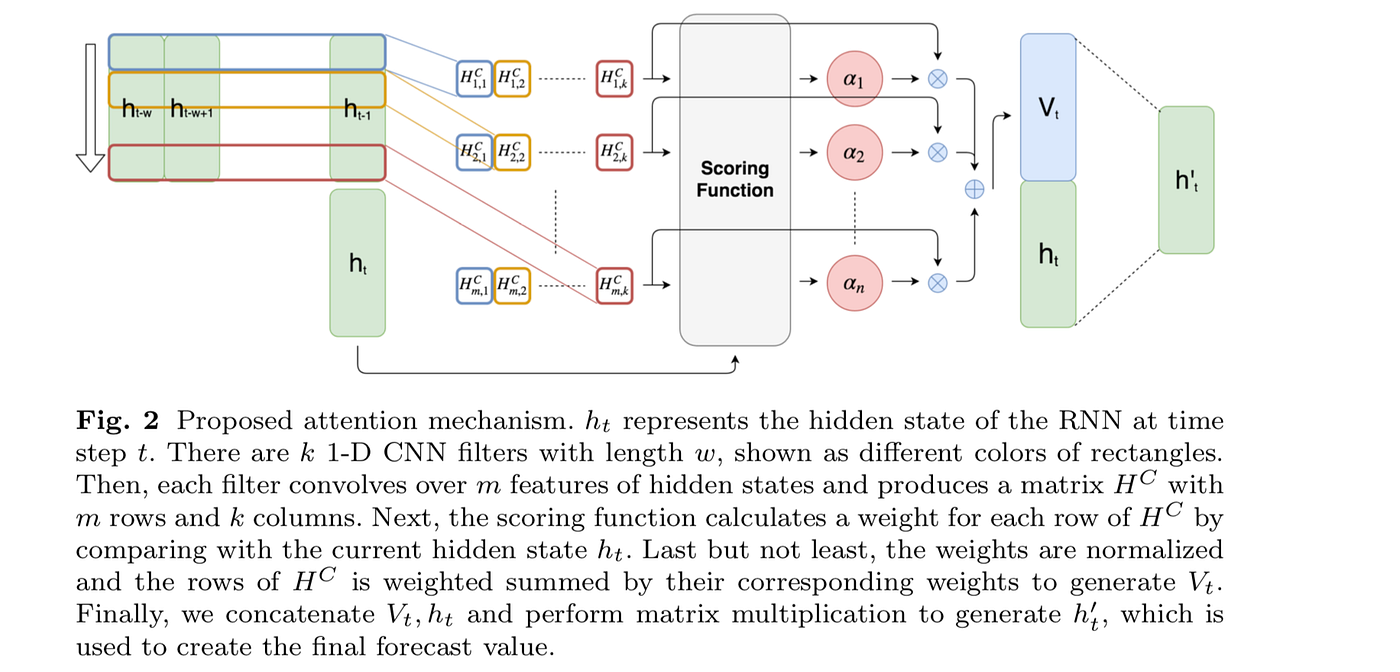
Image from Shih et. al., "Temporal Pattern Attention for Multivariate Time Series Forecasting", ArXiv, 2019.
The Temporal Pattern Attention LSTM network is based on the paper "Temporal Pattern Attention for Multivariate Time Series Forecasting" by Shih et. al.. It claims to have a better performance than LSTnet, with the additional advantage that an attention mechanism automatically tries to determine important parts of the time series, instead of introducing parameters that need to be optimized by the user.
The code is based on a PyTorch implementation by Jing Wang of the same model with slight adjustments.
Network Structure
The neural net consists of the following elements: The first part consists of an embedding and stacked LSTM layer made up of the following parts:
- A
Denseembedding layer for the input data. - A
StackedLSTMlayer for the transformed input data.
The temporal attention mechanism consist of
- A
Denselayer that transforms the hidden state of the last LSTM layer in theStackedLSTM. - A convolutional layer operating on the pooled output of the previous layer, estimating the importance of the different datapoints.
- A
Denselayer operating on the LSTM hidden state and the output of the attention mechanism.
A final Dense layer is used to calculate the output of the network.
Stacked LSTM
The stacked version of a number of LSTM cells is obtained by feeding the hidden state of one cell as input to the next one. Flux.jl's standard setup only allows feeding the output of one cell as the new input, thus we adjust some of the internals:
- Management of hidden states in
Fluxis done by theRecurstructure, which returns the output of a recurrent layer. We use aHiddenRecurstructure instead which returns the hidden state. - The
StackedLSTM-function chains everything together depending on the number of layers. (One layer corresponds to a standardLSTMcell.)