DARNN
The "Dual-Stage Attention-Based Recurrent Neural Network for Time Series Prediction" is based on the paper by Qin et. al.. See also the corresponding blog post.
The code is based on a PyTorch implementation of the same model with slight adjustments.
Network Structure
The neural network has a rather complex structure. Starting with an encoder-decoder structure, it consists of two units, one called the input attention mechanism, and a temporal attention mechanism.
The input attention mechanism feeds the input data to a LSTM network. In subsequent calculations, only its hidden state is used, where additional network layers try to estimate the importance of different hidden variables.
The temporal attention mechanism takes the hidden state of the encoder network and combines it with the hidden state of another LSTM decoder. Additional network layers try again to estimate the importance of the hidden variables of the encoder and decoder combined.
Linear layers combine the output of different layers to the final time series prediction.
The encoder part made up of the following:
- A
LSTMencoder layer. Only the hidden state is used for the output of the network. - A feature attention layer consisting of two
Denselayers withtanhactivation function for the first layer.
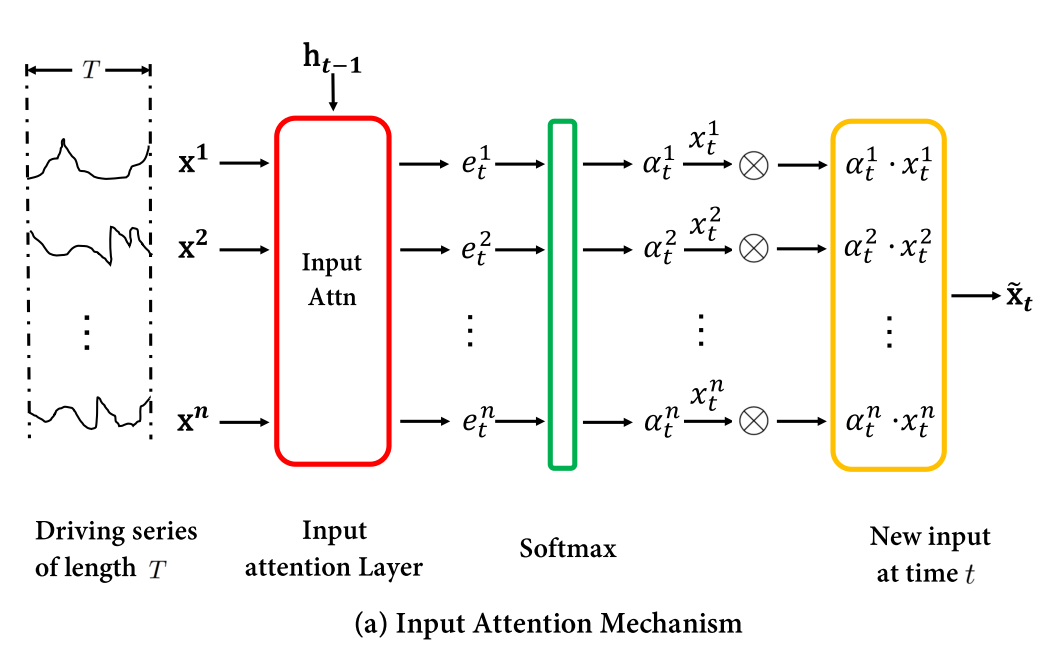
Encoder Structure. Image from Qin et. al., "Dual-Stage Attention-Based Recurrent Neural Network for Time Series Prediction", ArXiv, 2017.
The decoder part consist of
- A
LSTMdecoder layer. It's hidden state is used for determining a scaling of the original time series. - A temporal attention layer operating on the hidden state of the encoder layer, consisting of two
Denselayers similar to the encoder. - A
Denselayer operating on the encoder output and the temporal attention layer. Its ouput gets fed into the decoder. - A
Denselayer to obtain the final output based on the hidden state of the decoder.
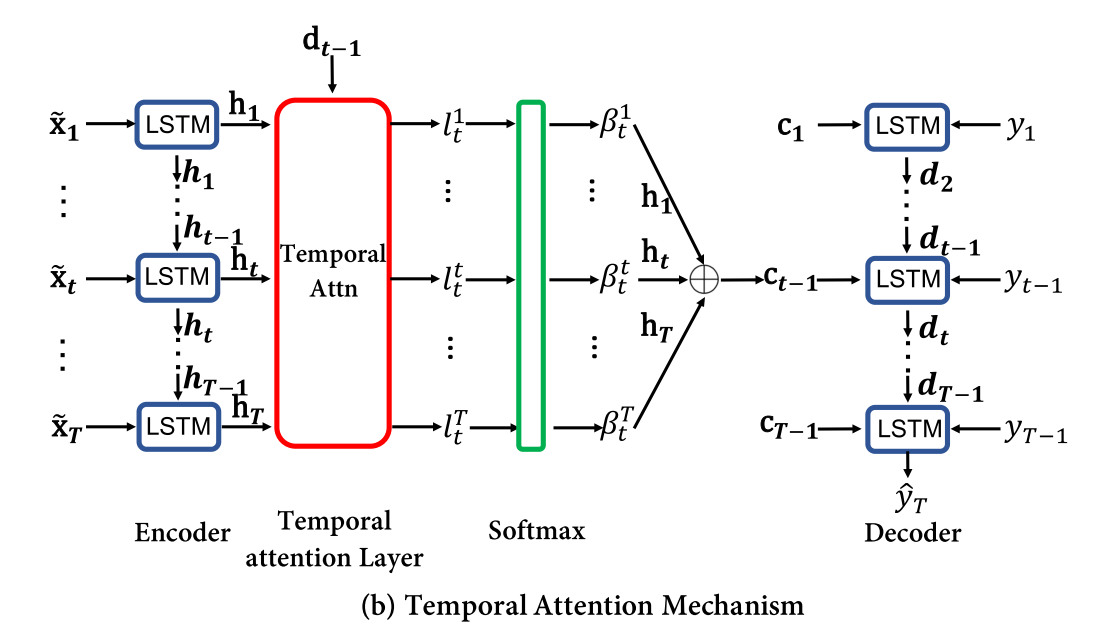
Decoder Structure. Image from Qin et. al., "Dual-Stage Attention-Based Recurrent Neural Network for Time Series Prediction", ArXiv, 2017.
Known Issues
Training of the DARNN layer is very slow, probably due to the use of Zygote.Buffer in the encoder.